8-(1) YOLO(You Only Look Once) 모델의 주요 특징과 장점은 무엇인가요?

🟢 YOLO(You Only Look Once) 모델의 주요 특징과 장점
YOLO(You Only Look Once)는 Object detection 분야에서 매우 광범위하게 활용되고 있는 모델이며 ultralytics라는 회사에서 개발한 YOLO 패키지는 사실상 표준처럼 활용되고 있다.
개인적으로 어떤 data에 가장 쉽게 딥러닝 모델을 적용해보고 싶다고 했을때 YOLO를 활용하고 있고 다양한 컴퓨터 비전에도 활용이 되고 있어서 이번에 간단하게 공부해보기로 했다.
⚪ Object detection이란?
Object detection = Classification + Regression
⚪ Object detection의 3대장: Faster R-CNN, SSD 그리고 YOLO
| 특징 | Faster R-CNN | SSD | YOLO |
|---|---|---|---|
| 핵심 철학 | 2-Stage (두 단계 접근) “신중하고 정확하게” | 1-Stage (한 단계 접근) “속도와 정확도의 균형” | 1-Stage (한 단계 접근) “인생은 한 방!” |
| 동작 방식 | 1. RPN: 객체 후보 영역 제안 2. Fast R-CNN: 분류 및 위치 보정 | CNN 중간의 여러 피처맵에서 다양한 크기의 객체를 동시에 탐지 | 이미지를 Grid로 나누고 각 셀에서 위치와 클래스를 동시에 예측 |
| 장점 | • 매우 높은 정확도⭐ • 작거나 겹친 객체 탐지에 강함 | • 속도와 정확도의 훌륭한 균형 • 다양한 크기의 객체 탐지 성능 좋음 | • 압도적으로 빠른 속도⭐ • 실시간 영상 처리에 최적화 |
| 단점 | • 상대적으로 느린 속도 • 구조가 복잡하고 무거움 | • Faster R-CNN보다 정확도 약간 낮음 • 아주 작은 객체 탐지는 여전히 어려움 | • 상대적으로 낮은 정확도 (초기 버전) • 작은 객체 탐지에 약함 |
| 대표 성능 | ~73.2% mAP ~7 fps (PASCAL VOC 2007) | ~74.3% mAP ~59 fps (PASCAL VOC 2007, SSD300) | ~63.4% mAP ~45 fps (PASCAL VOC 2007, YOLOv1) |
| 주요 사용처 | • 의료 영상 분석⭐ • 위성 사진 판독 • 정확도가 최우선인 연구 | • 대부분의 실용적인 앱 • 임베디드 시스템 • 적당한 성능과 속도가 모두 필요할 때 | • 실시간 CCTV 감시 • 자율 주행 • 빠른 반응 속도가 생명일 때 |
| 출처 논문 | Ren, S., et al. (2015). Faster R-CNN | Liu, W., et al. (2016). SSD | Redmon, J., et al. (2016). YOLO |
약간의 Detection 실수는 괜찮지만, 실시간으로 끊김 없이 화면을 분석해야 한다면 YOLO를 사용.
YOLO는 v1, v2, v3를 넘어 Alexey Bochkovskiy의 YOLOv4, Ultralytics의 YOLOv5, 그리고 현재의 YOLOv8, v9, v10에 이르기까지 끊임없이 발전됨.
많은 벤치마크에서 Faster R-CNN 계열의 정확도를 뛰어넘으면서도 속도는 수십 배 빠른 말도 안 되는 성능을 보여줌⭐
특히 Ultralytics 같은 회사들이 YOLO를 PyTorch 기반으로 접근성이 매우 높아 fine tuning 등 적용이 매우 쉬움
결론은 Object deatection에서 YOLO가 이미 압도적 대세❗
⚪ YOLO(You Only Look Once)
엄청나게 눈이 좋은 사람이 사진을 딱 한 번 슥 훑어보고, ‘저기 고양이 있고, 저쪽엔 개가 있네’ 라고 동시에 모든 걸 찾아내는 것
이전 모델들은 사진을 돋보기로 여기저기 수천 번씩 뜯어보면서 “여긴가? 아닌가?”를 반복
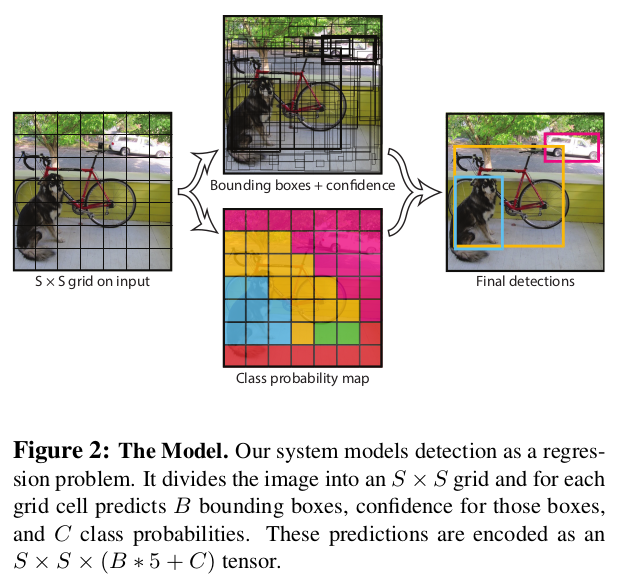
(1) 이미지를 grid로 나누기
이미지를 바둑판처럼 나눈다.
(2) 각 칸의 동시 예측 (Prediction)
각 칸이 동시에 ‘상자 위치’, ‘상자 신뢰도’, ‘객체 클래스’를 예측한다.
(3) 겹치는 예측들 정리하기 (Non-Maximum Suppression)
겹치는 상자들을 지우고 가장 좋은 예측만 남긴다.
🟢 Ultralytics의 YOLO

Ultralytics의 YOLO는 PyTorch 기반으로 만들어진, 아주 사용하기 쉽고 성능 좋은 YOLO 시리즈 구현체라고 할 수 있다.
⚪ Ultralytics YOLO란?
YOLOv3 시절부터 인기를 끌기 시작해서, 특히 YOLOv5를 통해 엄청나게 유명해졌음. 최근에는 YOLOv8을 중심으로 객체 탐지뿐만 아니라 다양한 컴퓨터 비전 작업을 지원하는 종합 프레임워크로 발전함.
쉽게 말해, 복잡한 설정 없이 바로 내 데이터에 최신 AI 모델을 적용해보고 싶을 때 가장 먼저 떠올리는 선택지 중 하나.
⚪ 핵심 특징 및 장점
1. 압도적인 사용 편의성
가장 큰 장점이다. 설치부터 학습, 추론까지의 과정이 정말 간단함.
1
2
3
4
5
6
7
8
# 설치
pip install ultralytics
# 학습 (내 데이터셋으로)
yolo train data=my_data.yaml model=yolov8n.pt epochs=100
# 예측
yolo predict model=yolov8n.pt source='image.jpg'
이렇게 몇 줄의 명령어로 모든 게 가능해서, 연구나 프로젝트의 프로토타입을 아주 빠르게 만들 수 있음.
2. PyTorch 기반 생태계
PyTorch를 기반으로 만들어져서 코드를 이해하고 수정하기가 쉽다. PyTorch에 익숙한 사람이라면, 모델 내부를 커스터마이징하거나 기존 프로젝트에 통합하기도 아주 편함.
3. 뛰어난 성능과 확장성
가볍고 빠른 모델(n, s)부터 정확도가 매우 높은 무거운 모델(l, x)까지 다양한 크기의 모델을 제공함. 그래서 사용자가 자신의 하드웨어와 목적에 맞게 속도와 정확도를 쉽게 조절할 수 있음.
4. 다양한 컴퓨터 비전(CV) 작업 지원
최신 YOLOv8은 단순한 객체 탐지를 넘어선 ‘종합 CV 툴킷’임.
- 객체 탐지 (Object Detection)
- 이미지 분할 (Segmentation)
- 자세 추정 (Pose Estimation)
- 객체 추적 (Tracking)
- 이미지 분류 (Classification)
이 모든 작업을 거의 동일한 방식으로 쉽게 수행할 수 있도록 지원함.
결론적으로 Ultralytics의 YOLO는 ‘빠른 개발 속도’와 ‘높은 성능’이라는 두 마리 토끼를 모두 잡아서, 이제는 수많은 개발자와 연구자들에게 필수적인 도구가 되었음.
🟢 예시 답안 (코드잇 제공)
- YOLO(You Only Look Once) 모델은 실시간 객체 탐지를 위해 설계된 딥러닝 기반의 객체 인식 모델입니다. 기존 객체 탐지 방법들은 여러 단계로 구성되어 있어 속도가 느렸지만, YOLO는 한 번의 Forward Pass만으로 객체의 위치와 클래스를 동시에 예측할 수 있기 때문에 매우 빠르게 동작합니다.
- YOLO의 주요 특징 중 하나는 그리드 기반 예측 방식입니다. 이미지 전체를 작은 그리드로 나누고, 각 그리드 셀에서 객체의 중심이 존재할 가능성을 예측하는 방식으로 동작합니다. 이를 통해 전체 이미지를 한 번에 분석하면서도 높은 연산 효율을 유지할 수 있습니다.
- 또한, YOLO는 엔드투엔드 방식(end-to-end approach)을 사용하여 모델이 이미지에서 직접 바운딩 박스와 클래스를 예측합니다. 이를 통해 속도가 빠르고 최적화가 용이하며, 실시간 객체 탐지가 필요한 자율주행, 보안 감시, 스포츠 분석 등의 분야에서 널리 활용되고 있습니다.
- YOLO의 가장 큰 장점은 빠른 속도와 높은 효율성입니다. 다른 객체 탐지 모델(R-CNN 계열)과 비교했을 때, YOLO는 몇 배 이상 빠르게 동작하면서도 상대적으로 높은 정확도를 유지합니다. 특히, 단일 네트워크 구조로 동작하기 때문에 실시간 응용이 가능하다는 점에서 강력한 장점을 가지고 있습니다.
- 그러나 YOLO는 상대적으로 작은 객체를 탐지하는 데 어려움을 겪을 수 있으며, 정확도를 높이기 위해 최신 버전(YOLOv3, YOLOv4, YOLOv5 등)에서 개선이 이루어지고 있습니다. 최신 버전에서는 앵커 박스(anchor box) 활용, 더 깊어진 네트워크 구조, 고해상도 입력 지원 등의 기술을 통해 정확도를 향상시키고 있습니다.