VAE: Variational Autoencoder
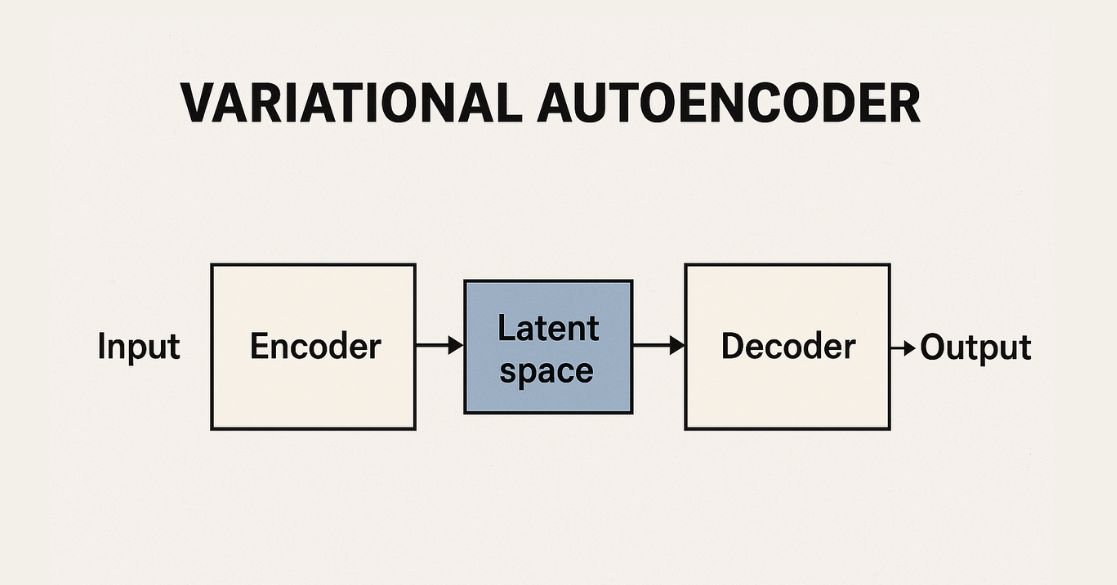
VAE: Variational Autoencoder
🟣 Intro
대표적인 generative model의 첫 번째 시리즈인 VAE에 대해서 정리해보려고 한다.
⚪ VAE (Variational AutoEncoder)란?
- VAE는 확률적 latent space를 학습하는 생성모델 (Generative Model) 이다. 기존의 AutoEncoder는 latent vector를 단순한 벡터로 압축하지만, VAE는 이를 확률분포로 본다.
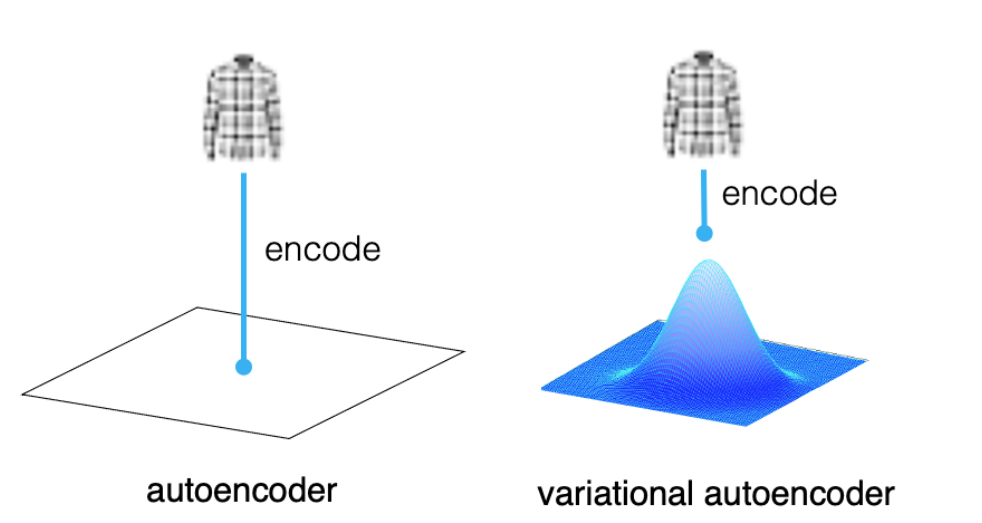
- 아이디어: 데이터를 잠재 공간(z)으로 인코딩 후 확률적으로 복원
- 수식: $p(x, z) = p(x|z)p(z)$
- 목적: ELBO (Evidence Lower Bound) 최적화
- 장점: 학습 안정, 확률 기반 생성
- 단점: 이미지가 흐릿할 수 있음
처음 공부할 때 ‘Variational’이라는 단어가 쉽게 와닿지 않아서 고생했었던 모델이었다..
⚪ 수식 정리
VAE의 목적은 다음의 evidence lower bound (ELBO)를 최대화하는 것:
\[\log p(x) \ge \mathbb{E}_{q(z|x)}[\log p(x|z)] - D_{KL}(q(z|x) \| p(z))\]- 첫 항: reconstruction term
- 두 번째 항: latent 분포를 정규 분포에 가깝게 유도
⚪ 구조 요약

- Encoder: 입력 \(x\) → latent 분포 \(z \sim \mathcal{N}(\mu, \sigma^2)\)
- Decoder: \(z\) → 복원된 이미지 \(\hat{x}\)
- Loss:
- 복원 손실: \(\|x - \hat{x}\|^2\)
- 분포 regularization (KL divergence): \(D_{KL}(q(z\|x) \| p(z))\)
⚪ 특징
| 항목 | 설명 |
|---|---|
| 장점 | Latent space가 연속적, sampling 가능 |
| 단점 | 이미지 품질이 blurry함 (pixel-wise loss 때문) |
| 응용 | Image generation, anomaly detection, disentanglement |
🟣 마치며
VAE의 핵심 아이디어는 인코더가 이미지를 잠재 공간의 특정 한 점(a single point) 으로 매핑하는 대신, 확률 분포(a probability distribution) 로 매핑하도록 해서 latent space가 부드럽게 채워지도록 했다.
이러한 아이디어는 딥러닝 공부에서 generative model의 이해를 돕고, 또한 통계적 역량을 늘릴 수 있는 유의미한 공부일 것이다.
Reference
This post is licensed under CC BY 4.0 by the author.