17-(1) 모델 서빙이란 무엇이며, 왜 필요한가요? 실제 서비스 환경에서 서빙 프레임워크가 어떤 역할을 하나요?
🟢 모델 서빙(Model Serving)은 AI 모델을 실제 서비스 환경(production environment) 에서 사용자나 애플리케이션이 쓸 수 있도록 배포(deploy) 하는 과정
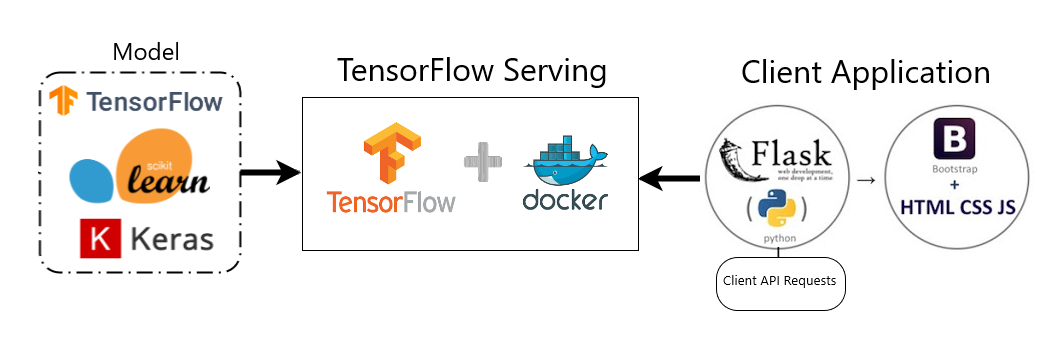
🟢 Intro
모델 서빙이란, 학습이 완료된 머신러닝/딥러닝 모델을 외부 요청(input)에 대해 예측 결과(output)을 반환할 수 있게 만드는 과정이다.
단순하게 생각하며 내가 설계한 코드를 model.predict()를 하면 되는것 아닌가? 생각할 수 있지만,
실제 서비스에는 다양한 요구사항과 이슈가 생긴다.
실시간 응답, 확장성, 안정성, 모니터링, 버전 관리, 보안…. 등
따라서 이러한 문제를 종합적으로 해결하기 위해서 서빙을 위한 프레임워크가 등장하였고 실시간으로 추론이 가능하게 하는 Production 과정이라고 이해하면 되겠다.
⚪ 1. 모델 서빙(Model Serving)이란?
모델 서빙(Model Serving)이란, 훈련(Training)이 완료된 머신러닝/딥러닝 모델을 실제 프로덕션(Production) 환경에 배포하여, 외부 사용자의 요청(Request)에 따라 추론(Inference) 결과를 반환(Response)할 수 있도록 하는 일련의 과정을 의미한다.
Jupyter Notebook이나 Python 스크립트에서 실행하는 model.predict(data)는 ‘연구’ 단계이다. ‘서빙’ 단계는 이 모델 파일을 서버에 올리고 API 엔드포인트(Endpoint)를 노출하여, 이 모델을 전혀 모르는 웹/앱 개발자도 쉽게 호출하여 사용할 수 있게 만드는 ‘배포’ 단계이다.
이 과정은 MLOps 파이프라인(개발-배포-운영)에서 ‘배포(Serve)’ 단계를 담당하며, AI 서비스의 핵심 구성 요소이다.
⚪ 2. 왜 모델 서빙이 필요한가?
모델을 개발하는 것과 실제 서비스로 운영하는 것은 전혀 다른 영역이다. 모델 서빙은 다음과 같은 프로덕션 환경의 요구사항을 만족시키기 위해 반드시 필요하다.
- 접근성 (Accessibility): 모델을 HTTP/gRPC와 같은 표준 프로토콜 기반의 API로 추상화한다. 이를 통해 Python이 아닌 Java, C#, JavaScript 등 어떤 언어의 클라이언트(Web, App)에서도 모델의 기능을 쉽게 호출할 수 있다.
- 성능 (Performance): 실제 서비스는 수천, 수만 명의 동시 접속을 견뎌야 한다. 모델 서빙은 낮은 응답 지연 시간(Low Latency)과 높은 처리량(High Throughput)을 보장해야 한다.
- 안정성 및 확장성 (Stability & Scalability): 24시간 365일 중단 없이 운영되어야 하며, 트래픽이 몰리면 자동으로 서버를 증설(Auto-scaling)할 수 있어야 한다.
- 관리 용이성 (Manageability): 모델은 한 번 배포하고 끝이 아니다. 성능이 개선된 v2, v3 모델을 기존 서비스 중단 없이(Zero-downtime) 교체하고, 여러 버전의 모델을 동시에 운영(A/B 테스트)할 수 있어야 한다.
⚪ 3. 왜 ‘Flask’가 아닌 ‘서빙 프레임워크’를 사용하는가?
“그냥 Flask나 FastAPI 같은 웹 프레임워크로 API 만들면 되는 것 아닌가?”라고 생각할 수 있다. 하지만 이는 트래픽이 적은 소규모 환경에서나 가능하다.
모델 서빙 프레임워크(Model Serving Framework) (e.g., NVIDIA Triton, TorchServe, TF Serving, KServe)는 앞서 언급한 프로덕션 환경의 복잡한 요구사항들을 전문적으로 처리하기 위해 설계된 ‘모델 서빙 전용 엔진’이다.
이러한 프레임워크가 제공하는 핵심 역할은 다음과 같다.
A. 고성능 추론 및 최적화
서빙 프레임워크는 Python 기반의 Flask와 달리, C++이나 Rust 등으로 작성되어 네트워크 통신 오버헤드가 매우 적다.
또한, ONNX Runtime, NVIDIA TensorRT, OpenVINO 같은 하드웨어 가속 추론 엔진과 직접 통합된다. 프레임워크는 요청이 들어오면, 이 최적화된 백엔드 엔진을 통해 GPU/CPU에서 가장 빠른 속도로 추론을 수행한다.
B. 동적 배치 (Dynamic Batching)
딥러닝 모델, 특히 GPU는 데이터를 1개씩 처리하는 것보다 32개, 64개씩 묶어서(Batch) 처리할 때 훨씬 높은 효율(Throughput)을 낸다.
서빙 프레임워크는 실시간으로 들어오는 요청(Batch=1)들을 잠시 큐(Queue)에 모았다가, 최적의 배치 크기(e.g., 32개)로 묶어 한 번에 GPU로 보낸 후, 다시 결과를 나눠서 응답하는 ‘동적 배치(Dynamic Batching)’ 기능을 자동으로 수행한다. 이는 Flask로 직접 구현하기 매우 까다로운 고급 기술이다.
C. 동시 실행 및 버전 관리 (Concurrency & Versioning)
- 모델 동시 실행(Concurrent Model Execution): 하나의 GPU에서 여러 개의 모델 인스턴스를 동시에 실행하여 GPU 자원을 효율적으로 활용한다.
- 모델 버전 관리(Model Version Management):
/v1/model/predict와/v2/model/predictAPI를 동시에 제공할 수 있다. 서비스 중단 없이 v1에서 v2로 트래픽을 점진적으로 전환하는 롤링 업데이트(Rolling Update)나 A/B 테스트가 용이하다.
D. 표준화된 관리 기능
모델 저장소(Model Repository) 관리, API 엔드포인트 자동 생성(HTTP/gRPC), 시스템 상태 모니터링(초당 요청 수, 에러율, GPU 사용률) 등 MLOps에 필요한 부가 기능들을 기본적으로 제공한다.
🟢 정리하면
정의
- 학습된 모델을 실제 서비스 환경에서 예측할 수 있도록 배포하는 과정
- 즉, 모델을 API 형태로 외부에 제공하여 inference를 수행하게 만드는 단계
필요성
- 실시간 응답, 확장성, 안정성, 버전관리, 보안 등 실제 서비스 요구사항 충족
🟢 예시 답안 (코드잇 제공)
모델 서빙이란 학습된 인공지능 모델을 실제 서비스 환경에 배포하여, 외부에서 들어오는 입력 데이터에 대해 예측 결과를 실시간으로 제공하는 과정을 의미합니다. 단순히 모델을 학습시키는 것에 그치지 않고, 이를 사용자나 다른 시스템이 사용할 수 있는 형태로 안정적으로 제공해야 비로소 AI 기술이 제품화되고 서비스로 이어질 수 있습니다.
모델 서빙이 필요한 이유는 크게 세 가지입니다. 첫째, 학습된 모델은 일반적으로 Jupyter Notebook이나 로컬 환경에서 동작하기 때문에 실시간 요청을 처리할 수 없습니다. 둘째, 서비스 환경에서는 다수의 사용자 요청에 대해 높은 안정성과 일관된 응답 속도를 요구하기 때문에, 서빙 전용 시스템이 필요합니다. 셋째, 모델은 지속적으로 업데이트되거나 개선되어야 하며, 이 과정에서 새로운 버전의 모델을 무중단으로 교체하거나 관리할 수 있어야 합니다.
실제 서비스 환경에서 모델 서빙 프레임워크는 다음과 같은 역할을 수행합니다. 먼저, 모델을 메모리에 올려두고 REST API 혹은 gRPC와 같은 인터페이스를 통해 외부 요청을 받을 수 있게 합니다. 또한, 배치 처리나 비동기 요청 등 다양한 서빙 전략을 통해 처리 효율을 높이고, 동시에 로깅과 모니터링을 통해 모델의 상태와 응답 성능을 실시간으로 추적할 수 있도록 도와줍니다. 더 나아가, 멀티 모델 로딩이나 A/B 테스트, Canary 배포 등 복잡한 운영 전략도 서빙 프레임워크를 통해 수행할 수 있습니다.
결론적으로, 모델 서빙은 AI 모델을 제품 수준의 서비스로 전환하기 위한 핵심 요소이며, 서빙 프레임워크는 이를 실현하기 위한 필수적인 기반 인프라 역할을 합니다.