생성형 모델(Generative Model)에 대한 이해
🟣 Generative Model: 생성형 모델에 대해서
생성형 모델은 과거 VAE, GAN 등 딥러닝 역사에서 다양한 연구가 이뤄져 왔으며 현재 diffusion을 비롯한 LLM까지 AI 산업 전반에서 사용이 되는 중요한 모델이다.
과거 generative model과 GAN은 거의 동의어로 사용된 기억이 있는데, 최근 diffusion model이 나오면서 generative model의 신뢰도가 상승하였다.
사실 기존의 GAN은 연구적으로 ‘신기한 발견’에 가까웠지 그걸 신중하게 사용하거나 산업적으로 활용이 많지는 않았다.
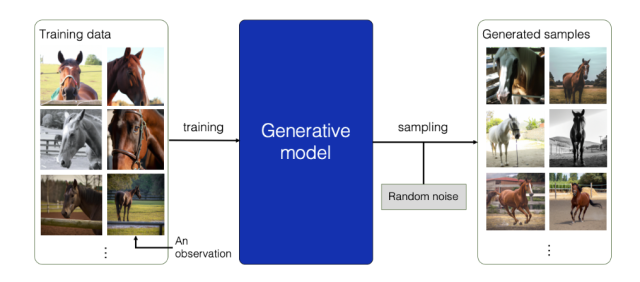
그러나 이제 인스타 광고나 어디에서나 생성형 모델이라는 단어를 찾아볼 수 있는 시대가 되면서 생성형 모델은 가장 중요한 패러다임이 되었다고 해도 과언은 아닐 것이다.
그래서 간략한 개념과 함께 연구 전반의 흐름을 정리하기 위해서 포스팅을 해보았다.
⚪ 확률 & 통계 관점에서 모델의 정의
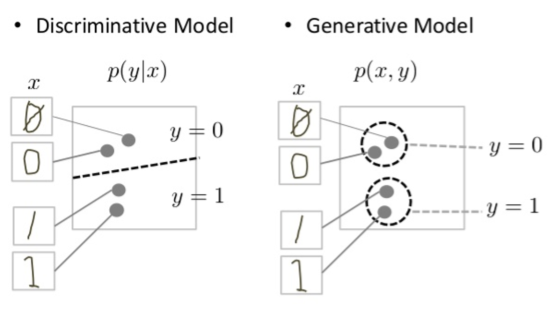
판별 모델(Discriminative Model): p(y | x)
“x가 주어졌을 때 y가 나올 확률”
- ex: 이미지 x가 주어졌을 때, 이게 고양이인지 개인지 분류.
- 조건부 확률 분포
생성형 모델(Generative Model): p(x, y)
“데이터 x와 y 전체가 어떻게 만들어지는지의 확률 분포를 모델링”
p(x|y)와p(y)를 따로 모델링해서 합치거나p(x, y)자체를 직접 모델링- 데이터가 어떤 확률 분포에서 왔는지 추정하고, 그 확률 분포에서 새로운 데이터를 sampling 하는 모델
$x_{new}$는 우리 모델이 학습한 확률 분포 $P_{model}$로부터 샘플린 된 새로운 데이터
⚪ 왜 생성형 모델이 중요한가?
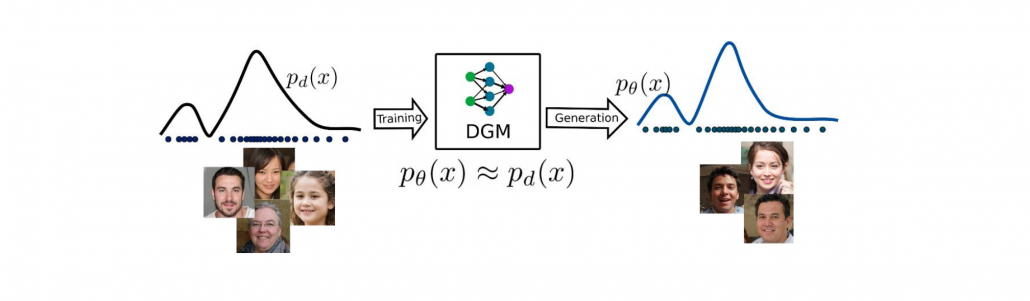
생성 모델은 단순히 신기한 그림을 그리는 기술을 넘어, 데이터의 본질적인 분포를 이해하고 활용하는 강력한 통계적 도구이며 다양한 산업에서 실제 활용되고 있는 대표적인 AI 기술
- 텍스트: GPT, LLM
- 이미지: GAN, Diffusion
- 오디오: WaveNet
⚪ 어떻게 데이터의 확률 분포를 학습할까?: Maximum Likelihood Estimation, MLE
우리가 가진 훈련 데이터가 우리 모델($P_{model}$)로부터 나왔을 확률(Likelihood)을 최대로 만드는 파라미터를 찾는 것.
$\theta$가 주어졌을 때 훈련 데이터 $X_{train}$이 나타날 Likelihood $L(\theta X_{train})$는 $P(X_{train} \theta)$와 같음. 이 때 이 likelihood를 최대로 만드는 $\theta$를 찾으면 된다
⚪ 대표적인 Generative model 3가지
1. VAE (Variational AutoEncoder)
- 아이디어: 데이터를 잠재 공간(z)으로 인코딩 후 확률적으로 복원
- 수식: $p(x, z) = p(x|z)p(z)$
- 목적: ELBO (Evidence Lower Bound) 최적화
- 장점: 학습 안정, 확률 기반 생성
- 단점: 이미지가 흐릿할 수 있음
2. GAN (Generative Adversarial Network)
- 아이디어: Generator와 Discriminator의 경쟁 구조
- 수식: $min_{G} max_{D} E[log D(x)] + E[log (1 - D(G(z)))]$
- 장점: 매우 샤프한 이미지 생성
- 단점: 학습 불안정, mode collapse 위험
3. Diffusion Model
- 아이디어: 노이즈를 점점 추가했다가, 다시 제거해서 원본 복원
- 수식: Reverse process $p(x_{t-1} | x_t)$를 학습
- 장점: 고해상도, 매우 정교한 생성
- 단점: 느림 (학습/샘플링 모두)
VAE는 수학적으로 안정적이고, GAN은 리얼하게 잘 만들고, Diffusion은 정교하게 천천히 만든다!
⚪ Generative model 논문 발전 과정
| 연도 | 논문명 (링크) | 저자/기관 | 핵심 기여 |
|---|---|---|---|
| 2013 | Auto-Encoding Variational Bayes | Kingma & Welling (ICLR 2014) | ⭐ 최초의 VAE 제안 |
| 2014 | Generative Adversarial Nets | Goodfellow et al. (NIPS 2014) | ⭐⭐ GAN 탄생: Generator vs Discriminator |
| 2015 | DCGAN | Radford et al. | GAN에 CNN 구조 도입 (Stable한 학습) |
| 2016 | PixelRNN / PixelCNN | van den Oord et al. | Autoregressive 방식으로 픽셀 단위 생성 |
| 2017 | Wasserstein GAN (WGAN) | Arjovsky et al. | GAN 학습 안정화 (Lipschitz + Wasserstein distance) |
| 2018 | StyleGAN | Karras et al. (NVIDIA) | 얼굴 이미지 생성의 획기적 성능 |
| 2019 | VQ-VAE | van den Oord et al. | 벡터 양자화를 도입한 VAE 변형 |
| 2020 | Denoising Diffusion Probabilistic Models (DDPM) | Ho et al. (Google Brain) | ⭐⭐⭐ 최초의 Diffusion 모델 인기 시작 |
| 2021 | GLIDE | OpenAI | 텍스트-조건부 Diffusion (image generation) |
| 2022 | Imagen | Google Brain | 고해상도 이미지 생성 (Text → Image) |
| 2022 | Stable Diffusion | CompVis | 공개형 텍스트-투-이미지 Diffusion 모델 |
| 2022 | DALLE-2 | OpenAI | CLIP+Diffusion 기반, 창의적 이미지 생성 |
| 2023 | Sora (비공개 연구) | OpenAI | 텍스트 → 영상으로 확장된 Diffusion 기반 |
| 2023 | LLaMA, GPT-4 등 LLM | Meta / OpenAI | 텍스트 기반 생성형 모델의 정점 |
🟣 마치며
생성형 모델은 데이터의 확률 분포를 만들고 데이터를 sampling 한다는 것이 핵심 개념이다.
다만 이것의 background로 사용되는 통계적인 base를 이해하여야 심층적인 연구가 가능하기 때문에 수식적으로 이해를 하는 것이 매우 중요하다는 것을 다시 한번 깨달으며… 이만💊