10-(3) Attention 메커니즘이 Seq2Seq 모델의 어떤 문제를 해결하는 데 도움이 되나요?
🟢 Attention 메커니즘이 Seq2Seq 모델의 어떤 문제를 해결하는 데 도움이 되나요?
NLP에서 Seq2Seq는 ‘정보 병목(Information Bottleneck)’ 현상이 가장 큰 한계였다. 즉, 기존 RNN 모델은 디코더에서 context vector에 현재까지 모든 정보를 담는 구조이기 때문에 정보가 소실되는 문제가 있었다.
그렇게 탄생한 것이 attention 매커니즘이고 단어 뜻 그대로 모든 정보가 아닌 선택적으로 정보를 취한다는 개념이다. 이러한 방식으로 정보의 병목을 해결하며 seq2seq 모델의 성능을 비약적으로 향상시켰다.
⚪ 문제점: 모든 정보를 하나의 ‘바구니’에 담으려는 시도
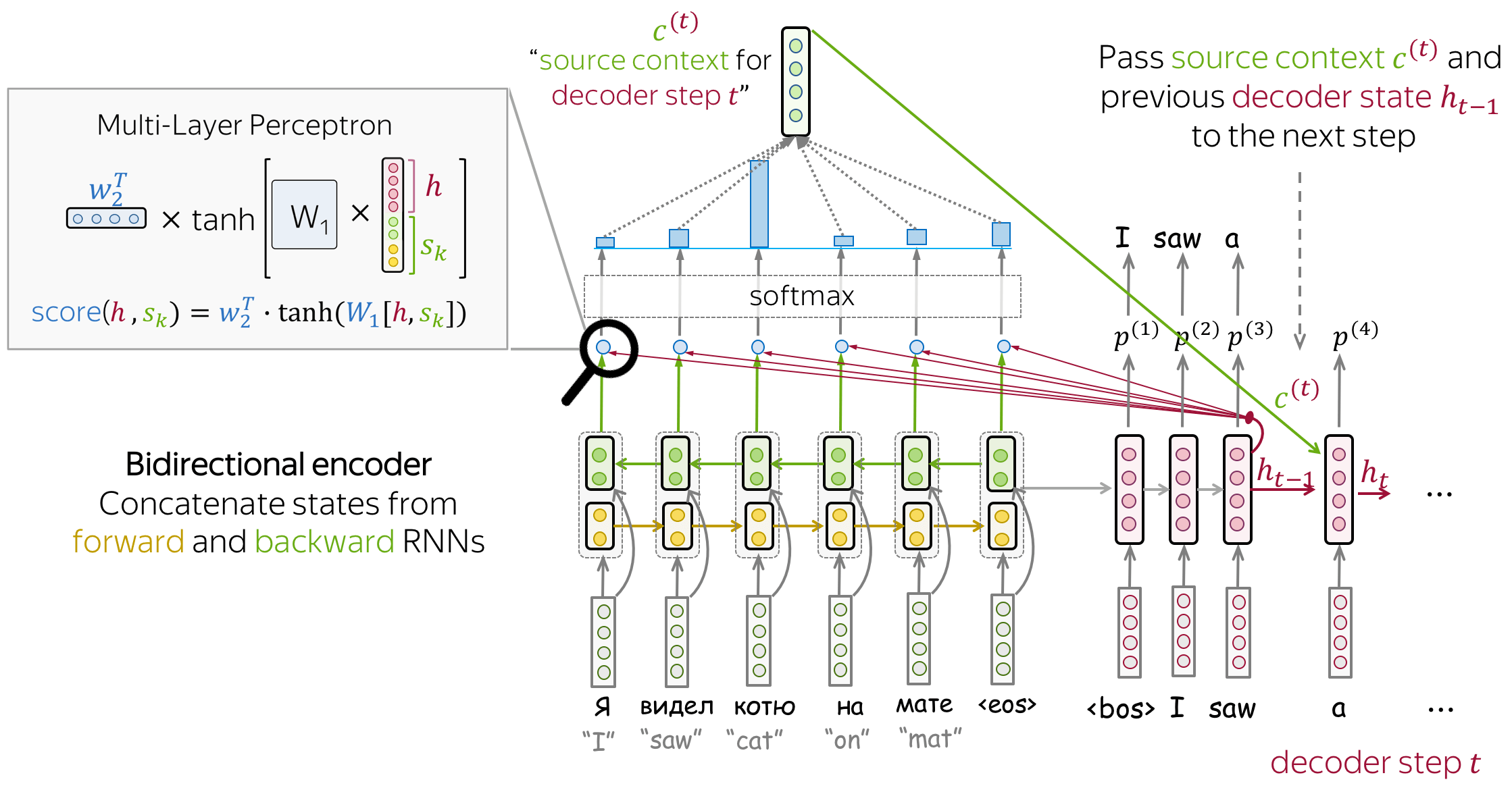
어텐션이 없던 기존의 Seq2Seq 모델은 다음과 같은 구조로 작동했음.

- 인코더(Encoder)가 입력 문장 전체를 읽고, 그 안에 담긴 모든 문맥적 의미를 하나의 고정된 크기 벡터(Context Vector)로 압축함.
- 디코더(Decoder)는 오직 이 벡터 하나에만 의존하여 출력 문장을 생성함.
이는 마치 장편 소설의 모든 내용을 단 한 문장으로 요약하려는 것과 같음. 문장이 길어지면 당연히 정보는 손실될 수밖에 없음. 특히 문장 앞부분의 중요한 정보는 뒤로 갈수록 희석되어, 정작 디코더는 핵심 정보를 놓친 ‘반쪽짜리 요약본’을 받게 됨. 이것이 바로 정보 병목 현상이며, 장기 의존성(Long-Term Dependency) 문제를 야기하는 주된 원인이었음.
⚪ 해결책: 필요할 때마다 ‘다시 찾아보기’
어텐션은 이 비효율적인 구조를 아주 직관적인 아이디어로 해결했음.
디코더가 단어를 생성하는 매 시점, 하나의 고정된 요약본만 보지 말고, 입력 문장 전체를 다시 참조하여 지금 생성할 단어와 가장 관련이 깊은 부분에 ‘집중(Attention)’하도록 하자.

즉, 어텐션은 디코더에게 일종의 ‘오픈북 시험’을 볼 권한을 준 것과 같음. 디코더는 단어를 하나씩 내뱉을 때마다 인코더의 모든 시점(모든 입력 단어의 정보)에 직접 접근할 수 있음.
이때 어떤 단어 정보에 더 집중할지를 결정하는 것이 어텐션 가중치(Attention Weight)이며, 이 가중치를 통해 매번 현재 시점에 가장 필요한 정보들로 구성된 새로운 ‘맞춤형’ 컨텍스트 벡터를 동적으로 생성함.
결론적으로 어텐션 메커니즘은 입력 문장의 정보를 하나의 벡터에 억지로 압축할 필요가 없게 만들어 정보 병목 현상을 해결하였고, 이를 통해 긴 문장에서도 문맥을 잃지 않는 뛰어난 성능을 확보하게 되었음. 이 아이디어는 이후 트랜스포머(Transformer) 모델의 핵심 구성 요소로 발전하며 현대 자연어 처리 기술의 근간이 되었음.
🟢 예시 답안 (코드잇 제공)
- Attention 메커니즘은 Seq2Seq(Sequence-to-Sequence) 모델이 가지는 중요한 한계를 해결하는 데 큰 도움을 줍니다.
- 기본적인 Seq2Seq 모델은 입력 시퀀스를 인코더가 하나의 고정된 벡터로 요약하고, 디코더는 이 벡터만을 바탕으로 전체 출력을 생성합니다. 그런데 입력 문장이 길어질수록, 인코더가 모든 정보를 하나의 벡터에 압축하는 데 한계가 생기고, 그로 인해 디코더는 필요한 문맥 정보를 충분히 받지 못하게 됩니다. 이로 인해 성능이 떨어지거나 문장의 앞부분은 잘 예측하면서도 뒷부분은 틀리는 문제가 자주 발생합니다.
- 이때 Attention 메커니즘을 적용하면, 디코더는 인코더의 전체 hidden state 중에서 매 시점에 필요한 부분에 ‘집중(attend)’해서 정보를 가져올 수 있게 됩니다. 즉, 입력 시퀀스 전체를 한꺼번에 압축하는 대신, 각 출력 단어를 생성할 때마다 입력 시퀀스의 특정 위치에 더 많은 가중치를 두고 참고할 수 있습니다.
- 이 덕분에 모델은 긴 문장에서도 필요한 문맥 정보를 유연하게 반영할 수 있고, 장기 의존성 문제(long-term dependency)를 완화할 수 있습니다. 결과적으로 번역, 문장 생성, 질의응답 같은 자연어 처리 과제에서 Seq2Seq 모델의 성능이 크게 향상됩니다.